Ethernet 10base-t (cкорости соединения компьютеров) → байт в секунду (b/s, единицы на базе байта (современные, на базе 1000))
Содержание:
- Этимология и история
- Значения других единиц, равные введённым выше
- Базовые единицы скорости передачи данных
- Единицы на базе байта (современные, на базе 1000)
- Единицы на базе байта (старые, на базе 1024)
- Время на передачу данных (современные единицы, на базе 1000)
- Время на передачу данных (старые единицы, на базе 1024)
- Скорость передачи на базе других интервалов времени (современные единицы, на базе 1000)
- Скорость передачи на базе других интервалов времени (старые единицы, на базе 1024)
- Файлы и файловые системы
- Общее использование
- Символ единицы
- Определение
- Зачем нам нужен порядок байтов
- Прямой порядок против обратного порядка
- Порядок байтов в памяти
- История и использование
- Битовый порядок байтов
- Заключение
Этимология и история
Термин « байт» был придуман Вернером Бухгольцем в июне 1956 года на ранней стадии разработки компьютера IBM Stretch , который имел адресацию к командам битов и переменной длины поля (VFL) с размером байта, закодированным в инструкции. Это намеренное respelling от укуса , чтобы избежать случайной мутации к биту .
Другое происхождение байтов для групп битов, меньших размера слова компьютера, и в частности групп из четырех битов , зафиксировано Луисом Дж. Дули, который утверждал, что придумал этот термин во время работы с Жюлем Шварцем и Диком Билером над системой противовоздушной обороны. называлась SAGE в лаборатории Линкольна Массачусетского технологического института в 1956 или 1957 году и была разработана совместно Rand , MIT и IBM. Позже в языке Шварца JOVIAL фактически использовался этот термин, но автор смутно напомнил, что он произошел от AN / FSQ-31 .
Ранние компьютеры использовали различные четырехбитные двоично-десятичные представления (BCD) и шестибитные коды для печатных графических шаблонов, распространенных в армии США ( FIELDATA ) и военно-морском флоте . Эти представления включали буквенно-цифровые символы и специальные графические символы. Эти наборы были расширены в 1963 году до семи битов кодирования, названного Американским стандартным кодом для обмена информацией (ASCII) в качестве Федерального стандарта обработки информации , который заменил несовместимые коды телетайпов, используемые различными ветвями правительства США и университетами в 1960-х годах. . ASCII включает в себя разделение букв верхнего и нижнего регистра и набор управляющих символов для облегчения передачи письменного языка, а также функций устройства печати, таких как перемещение страницы и перевод строки, а также физическое или логическое управление потоком данных во время передачи. СМИ. В начале 1960-х, будучи также активным в стандартизации ASCII, IBM одновременно представила в своей линейке продуктов System / 360 восьмибитовый расширенный двоично-десятичный код обмена (EBCDIC), расширение их шестибитного двоично-десятичного кода (BCDIC). ) представления, использованные в более ранних перфорациях карт. Известность System / 360 привела к повсеместному внедрению восьмибитного размера памяти, в то время как в деталях схемы кодирования EBCDIC и ASCII различаются.
В начале 1960-х годов AT&T представила цифровую телефонию на междугородних магистральных линиях . Они использовали восьмибитное кодирование по закону μ . Эти крупные вложения обещали снизить затраты на передачу восьмибитных данных.
Разработка восьмиразрядных микропроцессоров в 1970-х годах популяризовала этот размер памяти. Микропроцессоры, такие как Intel 8008 , прямой предшественник и , использовавшиеся в ранних персональных компьютерах, также могли выполнять небольшое количество операций с четырехбитными парами в байте, например, десятичное добавление-регулировка ( DAA) инструкция. Некоторое количество четырех бит часто называют полубайт , также Nybble , который удобно представлен одной шестнадцатеричной цифрой.
Термин октет используется для однозначного определения размера в восемь бит. Он широко используется в определениях протоколов .
Исторически термин « октад» или « октад» также использовался для обозначения восьми битов, по крайней мере, в Западной Европе; однако это использование больше не является обычным явлением. Точное происхождение этого термина неясно, но его можно найти в британских, голландских и немецких источниках 1960-х и 1970-х годов, а также в документации по мэйнфреймам Philips .
Значения других единиц, равные введённым выше
открыть
свернуть
Базовые единицы скорости передачи данных
|
байт в секунду → терабит в секунду (Tbps) |
|
|
байт в секунду → гигабит в секунду (Gbps) |
|
байт в секунду → мегабит в секунду (Mbps) |
|
|
байт в секунду → килобит в секунду (Kbps) |
|
|
байт в секунду → бит в секунду (bps) |
Единицы:
терабит в секунду
(Tbps)
/
гигабит в секунду
(Gbps)
/
мегабит в секунду
(Mbps)
/
килобит в секунду
(Kbps)
/
бит в секунду
(bps)
открыть
свернуть
Единицы на базе байта (современные, на базе 1000)
Современное определение килобайта — 1000 байт, т.к. префикс кило- всегда означает 1000. Но ранее было принято считать, что в килобайте 1024 байта. В этой секции приводится перевод величин для современного определения килобайта.
|
байт в секунду → терабайт в секунду (TB/s) |
|
|
байт в секунду → гигабайт в секунду (GB/s) |
|
байт в секунду → мегабайт в секунду (MB/s) |
|
|
байт в секунду → килобайт в секунду (KB/s) |
|
|
байт в секунду → байт в секунду (B/s) |
Единицы:
терабайт в секунду
(TB/s)
/
гигабайт в секунду
(GB/s)
/
мегабайт в секунду
(MB/s)
/
килобайт в секунду
(KB/s)
/
байт в секунду
(B/s)
открыть
свернуть
Единицы на базе байта (старые, на базе 1024)
Ранее было принято считать, что в килобайте 1024 байта. Во избежание путаницы международный стандарт IEC 1998 года переименовал единицы на базе 1024 с использованием префиксов киби, меби, гиби вместо кило, мега, гига.
|
байт в секунду → тебибайт в секунду (TiB/s) |
|
|
байт в секунду → гибибайт в секунду (GiB/s) |
|
байт в секунду → мебибайт в секунду (MiB/s) |
|
|
байт в секунду → кибибайт в секунду (KiB/s) |
|
|
байт в секунду → байт в секунду (B/s) |
Единицы:
тебибайт в секунду
(TiB/s)
/
гибибайт в секунду
(GiB/s)
/
мебибайт в секунду
(MiB/s)
/
кибибайт в секунду
(KiB/s)
/
байт в секунду
(B/s)
открыть
свернуть
Время на передачу данных (современные единицы, на базе 1000)
| байт в секунду → секунда на мегабайт | |
| байт в секунду → секунда на гигабайт | |
| байт в секунду → минута на мегабайт |
| байт в секунду → минута на гигабайт | |
| байт в секунду → час на мегабайт | |
| байт в секунду → час на гигабайт |
Единицы:
секунда на мегабайт
/
секунда на гигабайт
/
минута на мегабайт
/
минута на гигабайт
/
час на мегабайт
/
час на гигабайт
открыть
свернуть
Время на передачу данных (старые единицы, на базе 1024)
| байт в секунду → секунда на мебибайт | |
| байт в секунду → секунда на гибибайт | |
| байт в секунду → минута на мебибайт |
| байт в секунду → минута на гибибайт | |
| байт в секунду → час на мебибайт | |
| байт в секунду → час на гибибайт |
Единицы:
секунда на мебибайт
/
секунда на гибибайт
/
минута на мебибайт
/
минута на гибибайт
/
час на мебибайт
/
час на гибибайт
открыть
свернуть
Скорость передачи на базе других интервалов времени (современные единицы, на базе 1000)
| байт в секунду → терабайт в минуту | |
| байт в секунду → гигабайт в минуту | |
| байт в секунду → мегабайт в минуту | |
| байт в секунду → килобайт в минуту | |
| байт в секунду → байт в минуту | |
| байт в секунду → терабайт в час | |
| байт в секунду → гигабайт в час | |
| байт в секунду → мегабайт в час | |
| байт в секунду → килобайт в час | |
| байт в секунду → байт в час |
| байт в секунду → терабайт в сутки | |
| байт в секунду → гигабайт в сутки | |
| байт в секунду → мегабайт в сутки | |
| байт в секунду → килобайт в сутки | |
| байт в секунду → байт в сутки | |
| байт в секунду → терабайт в неделю | |
| байт в секунду → гигабайт в неделю | |
| байт в секунду → мегабайт в неделю | |
| байт в секунду → килобайт в неделю | |
| байт в секунду → байт в неделю |
Единицы:
терабайт в минуту
/
гигабайт в минуту
/
мегабайт в минуту
/
килобайт в минуту
/
байт в минуту
/
терабайт в час
/
гигабайт в час
/
мегабайт в час
/
килобайт в час
/
байт в час
/
терабайт в сутки
/
гигабайт в сутки
/
мегабайт в сутки
/
килобайт в сутки
/
байт в сутки
/
терабайт в неделю
/
гигабайт в неделю
/
мегабайт в неделю
/
килобайт в неделю
/
байт в неделю
открыть
свернуть
Скорость передачи на базе других интервалов времени (старые единицы, на базе 1024)
| байт в секунду → тебибайт в минуту | |
| байт в секунду → гибибайт в минуту | |
| байт в секунду → мебибайт в минуту | |
| байт в секунду → кибибайт в минуту | |
| байт в секунду → байт в минуту | |
| байт в секунду → тебибайт в час | |
| байт в секунду → гибибайт в час | |
| байт в секунду → мебибайт в час | |
| байт в секунду → кибибайт в час | |
| байт в секунду → байт в час |
| байт в секунду → тебибайт в сутки | |
| байт в секунду → гибибайт в сутки | |
| байт в секунду → мебибайт в сутки | |
| байт в секунду → кибибайт в сутки | |
| байт в секунду → байт в сутки | |
| байт в секунду → тебибайт в неделю | |
| байт в секунду → гибибайт в неделю | |
| байт в секунду → мебибайт в неделю | |
| байт в секунду → кибибайт в неделю | |
| байт в секунду → байт в неделю |
Единицы:
тебибайт в минуту
/
гибибайт в минуту
/
мебибайт в минуту
/
кибибайт в минуту
/
байт в минуту
/
тебибайт в час
/
гибибайт в час
/
мебибайт в час
/
кибибайт в час
/
байт в час
/
тебибайт в сутки
/
гибибайт в сутки
/
мебибайт в сутки
/
кибибайт в сутки
/
байт в сутки
/
тебибайт в неделю
/
гибибайт в неделю
/
мебибайт в неделю
/
кибибайт в неделю
/
байт в неделю
Файлы и файловые системы
Распознавание порядка байтов важно при чтении файла или файловой системы, созданных на компьютере с другим порядком байтов.
Некоторые наборы инструкций ЦП обеспечивают встроенную поддержку замены байтов с порядком байтов, например ( x86 — и новее) и ( ARMv6 и новее).
Некоторые компиляторы имеют встроенные средства для обмена байтами. Например, Intel Fortran компилятор поддерживает нестандартное спецификатор при открытии файла, например: .
Некоторые компиляторы имеют параметры для генерации кода, которые глобально разрешают преобразование для всех операций ввода-вывода файлов. Это позволяет повторно использовать код в системе с обратным порядком байтов без модификации кода.
Последовательные неформатированные файлы Fortran, созданные с одним порядком байтов, обычно не могут быть прочитаны в системе с использованием другого порядка байтов, потому что Fortran обычно реализует запись (определенную как данные, записанные одним оператором Fortran) как данные, которым предшествуют и после которых следуют поля счетчика, которые являются целыми числами, равными к количеству байтов в данных. Попытка прочитать такой файл с помощью Fortran в системе с другим порядком байтов приводит к ошибке времени выполнения, поскольку поля счетчика неверны. Этой проблемы можно избежать, записав последовательные двоичные файлы вместо последовательных неформатированных
Обратите внимание, однако, что относительно просто написать программу на другом языке (таком как C или Python ), которая анализирует последовательные неформатированные файлы Fortran с «чужим» порядком байтов и преобразует их в «родной» порядок байтов путем преобразования из «чужого» порядка байтов, когда чтение записей и данных Fortran.
Текст Unicode может необязательно начинаться с метки порядка байтов (BOM), чтобы обозначить порядок байтов в файле или потоке. Его кодовая точка — U + FEFF. В UTF-32 , например, большой обратный порядок байт файла должен начинаться с ; прямой порядок байтов должен начинаться с .
Форматы двоичных данных приложения, такие как, например, файлы MATLAB .mat или формат данных .bil , используемые в топографии, обычно не зависят от порядка байтов. Это достигается за счет сохранения данных всегда с фиксированным порядком байтов или переноса с данными переключателя, указывающего на порядок байтов.
Примером первого случая является двоичный формат файла XLS , который переносится между системами Windows и Mac и всегда с прямым порядком байтов, оставляя приложение Mac заменять байты при загрузке и сохранять при работе на процессоре Motorola 68K или PowerPC с прямым порядком байтов. .
Файлы изображений TIFF являются примером второй стратегии, заголовок которой сообщает приложению о порядке байтов их внутренних двоичных целых чисел. Если файл начинается с подписи, это означает, что целые числа представлены с прямым порядком байтов, а означает — с прямым порядком байтов. Для каждой из этих подписей требуется одно 16-битное слово, и они являются палиндромами (то есть они читают одно и то же вперед и назад), поэтому они не зависят от порядка байтов. означает Intel и означает Motorola , соответствующих поставщиков процессоров для совместимых платформ IBM PC (Intel) и Apple Macintosh (Motorola) в 1980-х годах. Процессоры Intel имеют прямой порядок байтов, а процессоры Motorola 680×0 — прямой порядок байтов. Эта явная подпись позволяет программе чтения TIFF при необходимости обменивать байты, когда данный файл был создан программой записи TIFF, запущенной на компьютере с другим порядком байтов.
Как следствие своей первоначальной реализации на платформе Intel 8080, файловая система таблицы размещения файлов (FAT), не зависящая от операционной системы, определяется с прямым порядком байтов, даже на платформах, изначально использующих другой порядок байтов, что требует операций перестановки байтов для поддержания жир.
Комбинированная файловая система ZFS / OpenZFS и менеджер логических томов, как известно, обеспечивают адаптивный порядок байтов и работают как с прямым, так и с прямым порядком байтов.
Общее использование
Многие языки программирования определяют байт типа данных .
В языках программирования C и C ++ байт определяется как « адресуемая единица хранения данных, достаточно большая, чтобы вместить любой член базового набора символов среды выполнения » (пункт 3.6 стандарта C). Стандарт C требует, чтобы интегральный тип данных unsigned char содержал как минимум 256 различных значений и был представлен как минимум восемью битами (пункт 5.2.4.2.1). Различные реализации C и C ++ резервируют 8, 9, 16, 32 или 36 бит для хранения байта. Кроме того, стандарты C и C ++ требуют, чтобы между двумя байтами не было промежутков. Это означает, что каждый бит в памяти является частью байта.
В Java примитивного типа данных байты определяются как восемь бит. Это тип данных со знаком, содержащий значения от -128 до 127.
В языках программирования .NET, таких как C #, байт определяется как беззнаковый тип, а sbyte — как подписанный тип данных, содержащие значения от 0 до 255 и от –128 до 127 соответственно.
В системах передачи данных байт используется как непрерывная последовательность битов в последовательном потоке данных, представляя наименьшую выделенную единицу данных. Блок передачи может дополнительно включать в себя стартовые биты, стоповые биты и биты четности , и, таким образом, его размер может варьироваться от семи до двенадцати битов, чтобы содержать один семибитовый код ASCII .
Символ единицы
Символ единицы для байта определен в IEC 80000-13 , IEEE 1541 и Metric Interchange Format как символ верхнего регистра B.
В Международной системе количеств (ISQ) B — символ бел , единицы логарифмического отношения мощности, названной в честь Александра Грэхема Белла , что противоречит спецификации IEC. Однако существует небольшая опасность путаницы, потому что ремень используется редко. Он используется в основном в своей десятичной доле, децибелах (дБ), для измерения силы сигнала и уровня звукового давления , в то время как единицы для одной десятой байта, децибайта и других дробей используются только в производных единицах, таких как как скорости передачи.
Строчная буква o для октета определена как символ для октета в IEC 80000-13 и обычно используется в таких языках, как французский и румынский , а также сочетается с метрическими префиксами для кратных чисел , например ko и Mo.
Термин « октада» (е) для восьми битов больше не используется.
Определение
- 1 МиБ = 2 20 байт = 1 048 576 байт = 1024 kibibytes
- 1024 МиБ = 1 гибибайт (ГиБ)
Префикс mebi — это двоичный префикс и множитель, производный от префикса SI mega и слова binary . Его значение равно 1024 2 , имеет ту же степень 1024, что и степень 1000 его десятичного аналога, префикса мега (1000 2 ).
Несмотря на свой официальный статус, мебибайт обычно не используется даже при подсчете количества байтов, рассчитанных в двоичных кратных, но часто представляется в виде мегабайта. Несоответствие может вызвать путаницу, поскольку операционные системы, использующие двоичный метод, сообщают более низкие числовые значения для размера хранилища, чем рекламируются производителями, такими как производители дисковых накопителей, которые строго используют десятичные единицы.
Зачем нам нужен порядок байтов
Несмотря на сатирическую трактовку Коэном борьбы «big endians» (прямого порядка, от старшего к младшему) против «little endians» (обратного порядка, от младшего к старшему), вопрос о порядке байтов на самом деле очень важен для нашей работы с данными.
Блок цифровой информации – это последовательность единиц и нулей. Эти единицы и нули начинаются с наименьшего значащего бита (least significant bit, LSb – обратите на строчную букву «b») и заканчиваются на наибольшем значащем бите (most significant bit, MSb).
Это кажется достаточно простым; рассмотрим следующий гипотетический сценарий.
32-разрядный процессор готов к сохранению данных и, следовательно, передает 32 бита данных в соответствующие 32 блока памяти. Этим 32 блокам памяти совместно назначается адрес, скажем 0x01. Шина данных в системе спроектирована таким образом, что нет возможности смешивать LSb с MSb, и все операции используют 32-битные данные, даже если соответствующие числа могут быть легко представлены в 16 или даже 8 битами. Когда процессору требуется получить доступ к сохраненным данным, он просто считывает 32 бита с адреса памяти 0x01. Эта система является надежной, и нет необходимости вводить понятие порядка байтов.
Возможно, вы заметили, что слово «байт» в описании этого гипотетического процессора нигде не упоминалось. Всё основано на 32-битных данных – зачем нужно делить эти данные на 8-битные части, если всё оборудование предназначено для обработки 32-битных данных? Вот здесь-то теория и реальность расходятся. Реальные цифровые системы, даже те, которые могут напрямую обрабатывать 32-битные или 64-битные данные, широко использую 8-битный сегмент данных, известный как байт.
Прямой порядок против обратного порядка
Прямой порядок (big endian) указывает на организацию цифровых данных, которая начинается с «большого» конца слова данных и продолжается в направлении «маленького» конца, где «большой» и «маленький» соответствуют наибольшему значащему и наименьшему значащему битам соответственно.
Обратный порядок (little endian) указывает на организацию, которая начинается с «маленького» конца и продолжается в направлении «большого» конца.
Решение между прямым и обратным порядками байтов не ограничивается схемами памяти и 8-разрядными процессорами. Байт является универсальной единицей в цифровых системах. Подумайте только о персональных компьютерах: пространство на жестком диске измеряется в байтах, ОЗУ измеряется в байтах, скорость передачи данных по USB указывается в байтах в секунду (или в битах в секунду), и это несмотря на тот факт, что 8-разрядные персональные компьютеры полностью устарели. Вопрос о порядке байтов вступает в игру всякий раз, когда цифровая система совмещает хранение или передачу данных на основе байтов с числовыми значениями, длина которых превышает 8 бит.
Инженеры должны знать о порядке байтов, когда данные хранятся, передаются или интерпретируются. Последовательная связь особенно восприимчива к проблемам с порядком байтов, поскольку байты, содержащиеся в многобайтовом слове данных, неизбежно будут передаваться последовательно, обычно либо от MSB до LSB, либо от LSB до MSB.
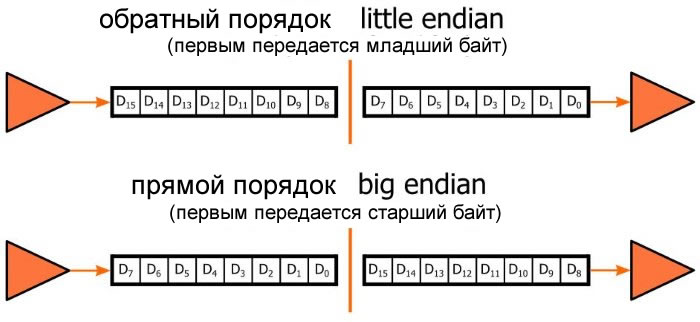 Порядок байтов в контексте последовательной передачи данных
Порядок байтов в контексте последовательной передачи данных
Параллельные шины не защищены от путаницы с порядком байтов, поскольку ширина шины может быть короче ширины данных. И в этом случае прямой или обратный порядок байтов должен быть выбран для параллельной побайтовой передачи данных.
Примером интерпретации на основе порядка байтов является случай, когда байты данных передаются от модуля датчика на ПК через «последовательный порт» (что в настоящее время почти наверняка означает, что в качестве COM порта используется USB соединение). Допустим, всё, что вам нужно сделать, это вывести эти данные, используя какой-то код MATLAB. Когда вы вводите эти байты в среду MATLAB и конвертируете их в обычные переменные, вы должны интерпретировать значения отдельных байтов в соответствии с порядком, в котором они хранятся в памяти.
Порядок байтов в памяти
Удобным средством демонстрации порядка байтов действии и объяснения разницы между прямым и обратным порядками является процесс хранения цифровых данных. Представьте, что мы используем 8-разрядный микроконтроллер. Всё аппаратное обеспечение в этом устройстве, включая ячейки памяти, предназначено для 8-битных данных. Таким образом, адрес 0x00 может хранить один байт, адрес 0x01 тоже хранит один байт, и так далее.
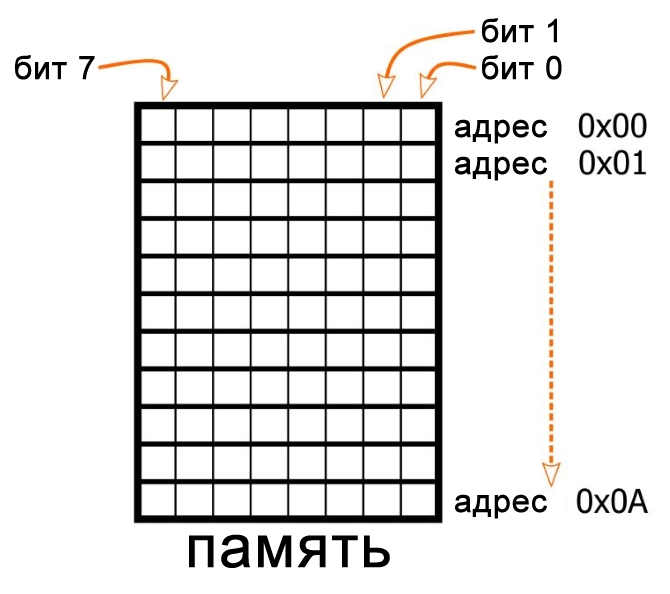 Эта схема показывает 11 байтов памяти, то есть 11 ячеек памяти, причем каждая ячейка хранит 8 бит данных
Эта схема показывает 11 байтов памяти, то есть 11 ячеек памяти, причем каждая ячейка хранит 8 бит данных
Допустим, мы решили запрограммировать этот микроконтроллер, используя компилятор C, который позволяет нам определять 32-разрядные (т.е. 4-байтовые) переменные
Компилятор должен хранить эти переменные в смежных ячейках памяти, но что не очень понятно, так это то, в самом младшем адресе памяти должен храниться наибольший значащий байт (most significant byte, MSB – обратите внимание на заглавную «B») или наименьший значащий байт (least significant byte, LSB)
Другими словами, должна ли система использовать порядок памяти от старшего к младшему (прямой порядок, big-endian) или от младшего к старшему (обратный порядок, little-endian)?
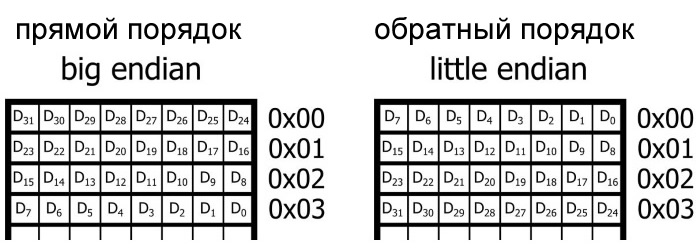 Хранение данных с прямым порядком и с обратным порядком. «D» относится к 32-разрядному слову данных, а номера индексов указывают на отдельные биты от MSb (D31) до LSb (D)
Хранение данных с прямым порядком и с обратным порядком. «D» относится к 32-разрядному слову данных, а номера индексов указывают на отдельные биты от MSb (D31) до LSb (D)
Здесь на самом деле нет правильного или неправильного ответа – любая договоренность может быть совершенно эффективной. Решение между прямым и обратным порядком может быть основано, например, на поддержании совместимости с предыдущими версиями данного процессора, что, конечно, поднимает вопрос о том, как инженеры приняли решение для первого процессора в этом семействе. Я не знаю; возможно, генеральный директор подбросил монету.
История и использование
Двоичные префиксы, включая mebi , были определены Международной электротехнической комиссией (IEC) в декабре 1998 года. Все основные органы по стандартизации одобрили их использование для двоичных кратных.
До этого официального определения мегабайт первоначально использовался в информатике для обозначения одного миллиона байтов (например, может хранить 35 миллионов байтов). Позже тот же термин «мегабайт» использовался для обозначения 1 048 576 байтов в контексте компьютерной памяти , хотя он продолжал обозначать ровно один миллион ( 1 000 000 ) байтов в контексте компьютерной памяти. Ошибка, связанная с этой неоднозначностью, относительно мала для мегабайта.
В 1995 году Межведомственный комитет Международного союза теоретической и прикладной химии по номенклатуре и символам решил попытаться разрешить эту двусмысленность, предложив новые префиксы для степеней 1024. Принято Международной электротехнической комиссией (МЭК), МЭК опубликовал стандарт в январе 1999 г.
Некоторые операционные системы по-прежнему вычисляют размер файла в мебибайтах, но сообщают количество в МБ (мегабайтах). Например, все версии операционной системы Microsoft Windows отображают файл размером 2 20 байтов как «1,00 МБ» или «1024 КБ» в диалоговом окне свойств файла и отображают файл размером 10 6 ( 1 000 000 ) байтов как 976 КБ.
Все версии операционных систем Apple имели одинаковое поведение до 2009 года с Mac OS X версии 10.6 , которая вместо этого использует мегабайты для всех размеров файлов и дисков, поэтому он сообщает о файле размером 10 6 байт как 1 МБ.
Разработчик Ubuntu Canonical реализовал обновленную политику единиц измерения в 2010 году, и начиная с Ubuntu 10.10 все версии используют двоичные префиксы IEC для величин base-2 и префиксы SI для величин base-10.
Битовый порядок байтов
Нумерация битов — это концепция, аналогичная порядку байтов, но на уровне битов, а не байтов. Порядок следования битов или порядок следования битов на уровне битов относится к порядку передачи битов по последовательной среде. Битовый аналог little-endian (младший бит идет первым) используется в RS-232 , HDLC , Ethernet и USB . Некоторые протоколы используют обратный порядок (например, телетекст , I 2 C , SMBus , PMBus и SONET и SDH ). Обычно существует согласованное представление битов независимо от их порядка в байте, так что последний становится актуальным только на очень низком уровне. Одно исключение вызвано функцией некоторых циклических проверок избыточности для обнаружения всех пакетных ошибок до известной длины, которая будет испорчена, если порядок битов отличается от порядка байтов при последовательной передаче.
Помимо сериализации, термины « порядок байтов» и « порядок байтов на уровне битов» используются редко, поскольку редко встречаются компьютерные архитектуры, в которых каждый отдельный бит имеет уникальный адрес. Доступ к отдельным битам или битовым полям осуществляется через их числовые значения или, в языках программирования высокого уровня, через присвоенные имена, последствия которых, однако, могут зависеть от машины или не иметь переносимости программного обеспечения .
Заключение
Очень жаль, что универсальная система порядка байтов не была создана еще в начале цифровой эпохи. Я даже не хочу знать, сколько коллективных часов человеческой жизни было посвящено решению проблем, вызванных несовпадающим порядком байтов.
В любом случае, мы не можем изменить прошлое, и мы также вряд ли убедим каждую компанию, производящую полупроводниковую технику и программное обеспечение, пересмотреть свои производственные линии для достижения единого универсального порядка байтов. Что мы можем сделать, так это добиваться согласованности наших собственных проектов и предоставлять четкую документацию, если существует вероятность конфликта между двумя составляющими частями системы.
